Preliminaries: KRL as a programming notation
KRL is the programming language for picos. It provides a notation for expressing how a pico will react to incoming events, and how it will respond to queries.
Superficially, although it is a very different language, it's syntax resembles that of JavaScript. There are blocks enclosed in curly braces, arithmetic and Boolean expressions, what look like assignment statements, function definitions and invocations, an if keyword, and so on. Notably missing are for and while keywords. And there are also constructs very different from what one would expect to see in a JavaScript program, such as keywords defaction, select when, and so forth.
So, it would be a mistake to think of KRL as being like JavaScript, because it has a very different execution model, and a very different memory model, besides the syntax differences. Like JavaScript, it has a run-time support system, the node pico engine. To compound the comparison, KRL is not interpreted, but rather compiles to JavaScript.
The unit of compilation is a ruleset, which is a set of rules in the sense that each rule name has to be unique, but actually more like a list of rules in the sense that the order in which they are written matters. Besides rules, the ruleset also has a place in which global functions can be defined, and at run-time, the functions when invoked evaluate within the context of the ruleset and the pico in which the ruleset is installed.
Common misconceptions
Depending on the languages you are most familiar with, you may naturally assume that KRL will behave in certain ways only to be unpleasantly surprised. Such surprises are documented in this section.
Request/Response vs. Event/Action and Query/Response
The node pico engine provides an interface to the picos it hosts which uses HTTP. Other transport mechanisms could (and will in the near future) be able to direct an event or a query to a pico.
If you are familiar with programming applications for HTTP, you may be tempted to equate a pico to a resource. In the RESTful programming model, an HTTP GET request should not modify the resource, while HTTP PUT and POST requests often do. With picos, a query can never modify the pico, and won't take any action on things outside the pico. Only an event sent to the pico can modify the pico's state. You may usefully think of a pico as being a state machine, with queries telling you about the state it is in, and events causing it to (possibly) change its state.
Queries to a pico
A query is sent to a pico by issuing a GET request to the pico engine which currently hosts it. The engine routes that request in such a way as to invoke a global shared function from one of the rulesets installed in the pico. Whatever value that function computes, given the current state of that pico, is packaged up and becomes the content of the HTTP response sent back to the event generator which issued the request. An event generator might be a program, a link in a web page, a link in the Testing tab of the UI, or even a developer using curl or the location bar of a web browser.
The URL used for a query has the following format (called the Sky Cloud API):
http://<domain>:<port>/sky/cloud/<ECI>/<RID>/<function name>?name0=value0&...&namen=valuen
The key to distinguishing a query from an event is to notice the first two components of the URL path, which will be exactly /sky/cloud/ and these are followed by the event channel identifier (which the node pico engine uses to identify which pico is to receive the query), and the ruleset identifier and function name (which the node pico engine uses to identify the ruleset (which must be installed in that pico) and the function (which must be defined and shared by that ruleset)). Finally, there are zero or more named arguments. The argument names must precisely match the argument names of the function, although order doesn't matter.
KRL is implemented in such a way that a function cannot change the state of the pico. Nor may it have any side effects on anything else*. In particular, an HTTP POST is not allowed from within a KRL function.
*A query should not be able to have actions on the outside world. However, KRL allows a function to perform an HTTP GET request, synchronously, so as to use information from a resource on the Internet as a part of its calculation. Ill-designed (from the RESTful perspective) resources may be changed by such a request.
Events to a pico
An event is sent to a pico by issuing a POST (or GET**) request to the pico engine which currently hosts the pico. The engine converts the HTTP request into an event to the pico. Many of the rules in any of the rulesets installed in the pico may be selected for evaluation. Ruleset are considered in a non-deterministic order, but within a ruleset the selected rules will be evaluated in the order written. Each rules may conditionally take action on other picos or the outside world in general (including HTTP POSTs), and may also have effects on the state of the pico. Furthermore, a rule may raise additional events (to the same pico) which will be processed as part of the original incoming event (See Raising Explicit Events in the Postlude). You might think of the original event as ricocheting within the boundary of the pico until things settle down, and all rules have had a chance to run. Only then will results specified by the rules be gathered together and packaged into an HTTP response to the event generator which issued the request. Any actions taken on the outside world happen as the rules are evaluated, but the results are not returned until event evaluation is complete. (See Event Loop Introduction for a more complete discussion).
The URL used for an event has the following format (called the Sky Event API):
http://<domain>:<port>/sky/event/<ECI>/<EID>/<event domain>/<event type>?name0=value0&...&namen=valuen
The key to distinguishing an event from a query is to notice the first two components of the URL path, which will be exactly /sky/event/ and these are followed by the event channel identifier (which the node pico engine uses to identify which pico is to receive the event), an event identifier (used to track event logging within the engine), and the event domain and event type (which are simple identifiers to distinguish one kind of event from another). Finally, there are zero or more named arguments. These become event attributes and are made available to the rules which select on the event, together with an attribute named _headers whose value is a map containing the HTTP request headers.
KRL is implemented in such a way that events can both take action (conditionally) on the world outside the pico, and change the state of the pico.
**For events, from the RESTful perspective, event generators should use an HTTP POST because the pico (viewed as a resource) may change as a result of the request. Some event generators may not be able to issue HTTP POST requests (for example, the location bar of a browser), so for convenience the node pico engine does accept a GET request for an event. Event generators embedded in programs, web pages, and even curl should use POST requests.
Name/Value binding vs. Variable assignment
In most programming languages, there is an assignment operation, which changes the value of a variable. It is often denoted by an equal sign. The left hand side of the equal sign evaluates to an address (sometimes called an l-value) in which resides the actual value. The right hand side of the equal sign evaluates to a value (sometimes called an r-value). The assignment statement causes whatever value is in the l-value location to be replaced by this r-value.
Name/Value binding in KRL
Unlike most programming languages, KRL does not use the equal sign for variable assignment. The left hand side is always a simple identifier – a name, which is bound to the value produced by the right hand side. From the point in the ruleset at which a binding occurs, that name refers to that value. If the binding occurs in a ruleset's global block, the binding is in force from that point on in the global block and throughout any of its rules. If the binding occurs within a rule, it is in force from that point on throughout the rule's evaluation.
Rebinding (another binding with the same name) is strongly discouraged (see declaration semantics). The krl-compiler and the krl-parser it embeds, and the IDE plugins will give a warning, "Duplicate declaration" when you do this.
In a rule, binding can occur explicitly in the rule's prelude (see declarations) and implicitly (without there being an equal sign) in the setting clause. A setting clause can occur as part of the rule selection (see Capturing Values) , as an outcome of an action (see User-Defined Actions), or as part of the foreach portion of a rule (see Looping in Rules).
Remember that name binding, or declaration, is very different from variable assignment.
Entity variable assignment
The state of a pico is maintained in entity variables.
The state of a pico can be changed only in the postlude of a rule, and since rules are evaluated only as part of a pico's reaction to an event, the state of a pico can be changed only by events.
An entity variable assignment works very much like variable assignment in many programming languages. The difference is that it is denoted by the colon-equals symbol := instead of a simple equals sign. The reason for the difference is so that programmers will be aware of the difference between changing the value of an entity variable and binding a name to a value. It was decided to use the longer symbol for its less frequent application, simply to save keystrokes.
Pico persistent state
A major advantage of using picos in distributed computations is that each pico maintains its own state. This is kept as the values of the entity variables used in each of the rulesets installed in the pico.
Picos follow the "actor" model from which they gain their power for concurrent computations. While many picos may be executing concurrently, each pico is only handling one message at a time. If other messages come in, they are queued up for later consideration.
A pico responds to two kinds of messages: queries and events, as introduced in the previous section. Picos also follow the "event condition action" pattern. When a rule reacts to an event, it conditionally takes actions. Then, it may mutate its state by assigning new values to its entity variables in the rule postlude.
A simplified grammar for a rule is shown here (extracted from a more complete grammar):
rule <rule_name> {
select when <event expression>
<prelude>
[ if <boolean expression> then ] <action>
<postlude>
}
When a rule selects, and is evaluated, it can have effects on the outside world by (conditionally) taking action (line 4). Changes to its own state can only happen in the postlude (line 5). Names can be bound to values in the event expression, the prelude, and for values returned by an action. But name-value binding doesn't change anything, either within the pico itself, or in the greater world.
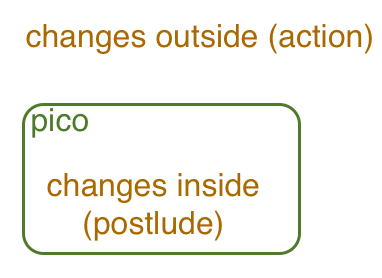
The stylized diagram below shows the pico as a boundary between itself and the outside world. Changes to itself can occur only when a selected rule changes an entity variable (as part of the rule's postlude). A selected rule can also, if conditions are met, take action on things outside of the pico.
Operators produce new values
KRL has a rich set of built-in Operators. However, they do not operate on structures to change them in-place. Rather they produce completely new structures.
This can lead to code like the following, which a programmer might expect to change an entity variable. Supposing ent:var contains the following structure (an array of maps):
[
{ "a": 1},
{ "b": 2}
]
then this map operation put might be expected to increment the value mapped from "b"
temp = ent:var;
temp[1].put("b",temp[1]{"b"}+1) // actually computes { "b": 3} but changes neither temp nor ent:var
The value computed by the second line is either discarded (since it is not bound to another name) or returned (if it were the last line of a function).
Even if these lines were part of a function which was invoked with its value assigned to the entity variable in a rule postlude, it would replace the array of maps with just one of the maps. Having the function return just temp would result in no change to the entity variable, because the operator didn't reach into the structure and make a change.
Order of rule evaluation
As noted earlier, when multiple rules within a ruleset select for an event, they will be evaluated in the order they appear in that ruleset. More precisely, the pico engine creates a list of rules to evaluate, called a "schedule" (See What Happens When an Event Is Raised?).
Once the schedule of rules has been created, the pico engine evaluates them in that order. The schedule shrinks by one each time a rule evaluation completes. Evaluation for the event ends when the schedule is empty.
The schedule can grow when one of the rules raises an event in its postlude. The pico engine determines which rules select on the raised event and adds all such rules to the end of the schedule. Since these rules are added to the end of the schedule, they will not evaluate until after all rules on the original schedule have evaluated. This can lead to unexpected evaluation orders. Within a ruleset, lexical ordering of rules determines evaluation ordering. But this applies each time the pico engine looks for rules selecting on an event. Once when the event is received from the outside world, and again whenever an event is raised.
Here is an example of such unexpected order of rule evaluation. We consider these three rules (from the ruleset published here) with unrelated portions elided. The set_up_url rule (lines 1-7) is used manually to establish a URL for use by the record_probe_temp_to_sheet rule (lines 16-26). We wanted the URL to change monthly, and a new rule was added and placed earlier so it would be evaluated first when the wovyn:new_temperature_reading event came in:
rule set_up_url {
select when probe_temp_recorder new_url url re#^(http.*)# setting(url)
fired {
ent:url := url;
ent:urlInEffectSince := time:now()
}
}
rule check_for_new_month {
select when wovyn new_temperature_reading
...
if new_month && new_url then noop()
fired {
raise probe_temp_recorder event "new_url" attributes { "url": new_url }
}
}
rule record_probe_temp_to_sheet {
select when wovyn new_temperature_reading where ent:url
pre {
...
}
http:post(ent:url,qs=data) setting(response)
fired {
...
ent:latestMonth := timestamp.substr(0,7);
}
}
Upon receiving the new temperature reading event, the pico engine schedules two rules for evaluation. First, we check for a new month (lines 8-15), preparatory to recording to a sheet. The idea is to change the URL for the first reading of a new month, before it gets recorded. When this happens, the check_for_new_month rule raises an event for the first rule to handle. The first rule comes first, right, so we might expect it to be evaluated before the third rule (and we did expect this – true story).
However any rules selected by a raised event are added at the end of the schedule. So, in this case, the rules actually evaluate in this order:
check_for_new_monthrecord_probe_temp_to_sheetset_up_url(for first reading of new month)
because the first two listed were added to the schedule when the event came in, while the third was only added to the schedule later during the evaluation of the first. So the first reading of a new month went to the old URL and subsequent readings for that month went to the new one.
The bug was fixed by repeating the postlude (lines 4-5) of the set_up_url rule as the postlude of the check_for_new_month rule (replacing line 13). It is tempting to avoid repetition of code (see DRY vs WET) by using rule chaining with raise but that doesn't work in a case like this.
https://en.wikipedia.org/wiki/Don%27t_repeat_yourself#DRY_vs_WET_solutions
Interference between rulesets
For queries, both the pico and the ruleset are specified in the /sky/cloud URL. However, for events, the ruleset is not specified. As shown in the Sky Event API page, the URL specifies the pico (by giving one of its ECIs) and the domain and type of the event. Any and all rulesets installed in the pico can react to an event, whereas for a query only the identified ruleset will respond.
When an event comes in to a pico, the engine looks at all of the rulesets installed in the pico (in an undetermined order). Every rule which selects on the event is added to a schedule of rules to evaluate (within a ruleset, rules will be added in the same order they appear in the ruleset). After all rulesets have contributed to the schedule, the engine begins to evaluate the rules selected, one after the other. If a rule postlude raises an event, the engine again examines all of the rulesets installed in the pico and adds the rules which select to the end of the schedule.
Usually only one or a few rules will select on a typical event, and often only a single ruleset will be involved. Rules within a ruleset typically use the same event domain, and that domain id is usually different from ruleset to ruleset. Even so, care must be taken to ensure that the rulesets installed in a pico do not interfere with each other.
As an example of what can go wrong, consider the wrangler:ruleset_installed event (discussed also in the Initializing entity variables and Wrangler pages). Whenever a ruleset is installed in a pico, Wrangler will raise this event. The engine will then consider all of the rulesets installed in the pico (including the one just installed). Unless you have a ruleset keeping track of all rulesets installed in a pico, you probably only want the rule in the ruleset just installed to select. The idiom commonly used to ensure this is shown here:
select when wrangler ruleset_installed where event:attr("rids") >< meta:rid
When Wrangler raises this event, one of the event attributes is an array of ruleset identifiers (for the rulesets installed) named rids and this where clause ensures that the rule can select only if that array contains the ruleset identifier of this ruleset. So, when other rulesets are installed in the pico later, this rule in this ruleset won't select.
For another example, when a pico requests the creation of a new child pico, Wrangler will raise the wrangler:new_child_created event to the parent pico once the new child pico exists (but before it has initialized itself). If any ruleset installed in the pico has a rule which selects for this event, that rule will be evaluated even if it doesn't apply.
The request for a new child pico usually originates from a rule evaluating within the parent pico:
raise wrangler event "new_child_request" attributes {
"name": random:uuid(),
"expr": expr, "txn_id": meta:txnId
}
In this case the child pico will have a random name, and the same backgroundColor as the parent pico. In addition to the required event attribute, this rule is asking for two other attributes to be included, named expr and txn_id (this example is taken from the Generate KRL code using KRL page). Once Wrangler has created the new child pico (per these specifications) it will raise the wrangler:new_child_created event (and all rules in all rulesets installed in the pico will have a chance to be selected).
The rule which the developer intends to select will be in the same ruleset and will look like this:
select when wrangler new_child_created
where event:attr("txn_id") == meta:txnId
The key to making this work is meta:txnId (part of the meta library) which is a unique identifier for this schedule of rules to evaluate. This ensures that this rule will select only one time, when the child pico it asked for is created. So if, later, the developer manually creates a new child pico in the developer UI About tab, this rule will not be selected.
Rule name vs event salience
This confusion is common among new KRL programmers. The name of a rule is not the same as the name of an event to which it is listening (which is salient for the rule).
rule send_twilio_sms_message {
select when twilio new_sms_message
...
}
The rule above is named send_twilio_sms_message but selects when the pico receives the twilio:new_sms_message event. The name is solely for reference (in logs for example) and must be unique within a ruleset. The select when clause is part of the declaration of what events are salient for this rule (or, as we say, for which the rule selects). Incidentally, notice that rule names are typically verbs while event names are usually nouns.
A common mistake would be to use the code below (perhaps in some other ruleset) to trigger the send_twilio_sms_message rule:
...
raise twilio event "send_twilio_sms_message" attributes { ... } // should be twilio event "new_sms_message"
...
This way of thinking is also evidence of a misconception: rules are not like procedures which we can call by raising an event.
Here is a common pattern which highlights the difference between rule names and salience:
rule check_for_a_known_number {
select when twilio new_sms_message
if ent:known_numbers >< event:attr("to") then noop()
notfired {
last
}
}
rule send_twilio_sms_message {
select when twilio new_sms_message
...
}
Notice two rules, with (of course) different names. But both select on the twilio:new_sms_message event, so they are both added to the rule evaluation schedule, and will be evaluated in the order they are written. If the to attribute is not in the list of known numbers (checked in line 3), the last keyword in line 5 of the postlude will empty the rule evaluation schedule. This means that even though the send_twilio_sms_message rule (of lines 8-11) was selected, it will not be evaluated.
Common errors
Sometimes a simple typo can cause hard-to-find bugs. Documented here are such incidents.
Regular expression capture groups
Using the setting clause with a capture group in the select when part of a rule, without having actually indicated a capture group in the regular expression.
select when phone incoming number re#\d{10}# setting(caller_id)
Here, the programmer expected to bind the name caller_id to a portion of the event attribute named number. But caller_id remains unbound (and thus evaluates to null when used) because no capture group was specified in the regular expression! A simple typo which can lead to a hard-to-find bug. It should have been written:
select when phone incoming number re#(\d{10})# setting(caller_id)
with the capture group indicated by enclosing it in parentheses.
Regular expression capture vs. explicit binding
At first glance, these two ways commonly used to bind an event attribute value to a name for use within a rule, appear to be equivalent:
select when console incoming attr_name re#(.+)# setting(local_name)
This code requires the event attribute attr_name to match the pattern (at least one character) or the rule will not even select. Because a regular expression operates on a single line of text, if the attribute value contained multiple lines, only the first line would be bound to the name local_name and any remaining lines would be discarded.
select when console incoming
pre {
local_name = event:attr("attr_name")
}
In this code, the entire value of the attribute attr_name is bound to the name local_name.
Functions and function calling
In KRL a function is defined and bound to a name.
The function later is used by referring to it by name, followed by arguments in parentheses. With functions which don't take arguments are used, it is easy to forget the () after the function name. Doing so, however, doesn't invoke the function, producing the expected value, but the function itself becomes the value. This can lead to astonishing errors.
Dots vs. colons vs. map references
Dots introduce operators. Dots should not be used to refer to a key within a map (a tendency of JavaScript programmers).
Colons appear between a module name (or library name) and the name of a value (often a function) provided by that user-defined module (or built-in library). If you (typo of course) use a dot instead of the colon, you'll get an unknown operator error message.
Map references use curly braces immediately following the map (or map name) and containing the key (or hash path) whose value is desired.
Array references use square brackets.
Map references and strings
It's easy to get a map reference wrong by typing a quoted name when a bare word is needed. In the code shown here, a string constant (the binding name) is used (in line 13) instead of the value bound to that name:
rule one {
...
if service then noop()
fired {
ent:se{service{"recipientKeys"}.head()} := service{"serviceEndpoint"}
}
}
rule two {
select when sovrin trust_ping_ping
pre {
...
their_key = event:attr("sender_key")
se = ent:se{"their_key"} // should be se = ent:se{their_key} without the quotes!
}
http:post(se,body=pm) setting(http_response)
}
The intention is that, in rule one we have (at line 5) a map named service, and we want to save its serviceEndpoint value, keyed by the first of its recipientKeys. We use ent:se (also a map) to hold this mapping from keys to endpoints. The bug in line 13 comes from getting confused about referencing something by its name (as done twice in line 5) with referencing something by the value a name maps to (as should have been done in line 13). Assuming that a recipient key will never be literally "their_key", line 13 will always set se to null and the http:post will always fail.
The empty string is not null
When using the Testing tab, and leaving a parameter field empty, it is a common error to expect that named event attribute to be null. Instead it is an empty string.
Using the Universal Operator isnull() against the event attribute will return false however, because the empty string is not null.
Similarly, using the Universal Operator defaultsTo() with the event attribute will not replace the empty string with the first argument to defaultsTo(). The following name/value binding will not work as expected when the event attribute named name is the empty string:
name = event:attr("name").defaultsTo(ent:name,"use stored name") // *name will be bound to the empty string
Instead, consider using the || operator:
name = event:attr("name") || ent:name // name will be bound to the value of ent:name if the event attribute is the empty string
See "Compound Predicates" in the Predicate Expressions page.
Regular expressions and case sensitivity
The String Operator match() takes a regular expression, which can be flagged as case-insensitive. If you forget to do this, it will return false when you expect it to return true.
For example, the first use of the match operator will return false but the second will return true as expected:
"1E4C9B93F3F0682250B6CF8331B7EE68FD8:3645804".match(re#1e4c9b93f3f0682250b6cf8331b7ee68fd8#) "1E4C9B93F3F0682250B6CF8331B7EE68FD8:3645804".match(re#1e4c9b93f3f0682250b6cf8331b7ee68fd8#i)
When a string is used to create a regular expression (using the Universal Operator as()), as in the first line of the following, there is no way yet to specify the needed i flag. So, in this case the second line shows a workaround (featuring the String Operator uc()).
"1E4C9B93F3F0682250B6CF8331B7EE68FD8:3645804".match("1e4c9b93f3f0682250b6cf8331b7ee68fd8".as("RegExp"))
"1E4C9B93F3F0682250B6CF8331B7EE68FD8:3645804".match("1e4c9b93f3f0682250b6cf8331b7ee68fd8".uc().as("RegExp"))
Operator precedence
Expressions involving infix operators won't normally require parentheses, but these can be used when the built-in precedence doesn't suit your needs.
Obscure bugs can occur. For example, this code (adapted from production code, from this ruleset):
html:header("Tic Tac Toe",css)
+ <<<h1>Tic Tac Toe</h1>
<h2>#{wrangler:name()}</h2>
<p>Playing: #{them}</p>
<p>State: #{state}#{state=="done" => " (winner: "+winner+")" | ""}</p>
<p>I am: #{me}</p>
>>
+ board
+ need_detail => <<<p>Moves: #{moves.encode()}</p>
>> | ""
+ js
+ html:footer()
Overall, the expression is concatenating strings. When one of them was meant to be conditionally included, the code of lines 9 and 10 was written. Whatever need_detail is, the string before the => is not empty and hence truthy, the entire expression evaluates to "<p>Moves: ... </p>". Both the concatenated string being tested by => and the one after the alternative | will not be part of the result. The ternary expression binds more loosely than string concatenation. The correct code would be:
html:header("Tic Tac Toe",css)
+ <<<h1>Tic Tac Toe</h1>
<h2>#{wrangler:name()}</h2>
<p>Playing: #{them}</p>
<p>State: #{state}#{state=="done" => " (winner: "+winner+")" | ""}</p>
<p>I am: #{me}</p>
>>
+ board
+ (need_detail => <<<p>Moves: #{moves.encode()}</p>
>> | "")
+ js
+ html:footer()
enclosing the ternary expression in parentheses. Notice that line 5 also includes a ternary expression, but this is enclosed within a beesting, avoiding the precedence problem.
Screenshot of the actual change made to the code:
