Importing data from other systems
- Bruce Conrad
Everything depends on the format that the other system can use to export its internal data. This page will discuss techniques for parsing various data interchange formats.
JSON would be preferable because it can easily be converted to a KRL map. Use the string operator decode on the JSON as-a-string to produce a KRL map.
CSV
Comma-separated values is a venerable data interchange format, and can be easily parsed with KRL functions. We will use the string operators split, replace, and extract, and the array operators tail, filter, and map, and the map operator filter.
For example here are a few lines of a spreadsheet containing data that we might want to import into a pico.
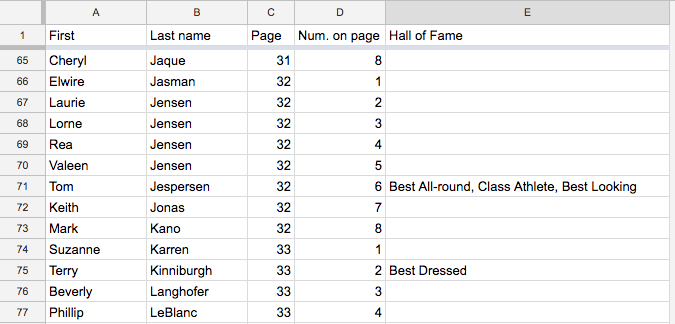
The first step is to have the spreadsheet export the data in CSV format. This same data, in CSV format shows some of the challenges involved in parsing the data. For this sample, inspection of the data showed no commas within the first and last name fields, but commas did appear for some records in the hall of fame column. In CSV format, such values will be surrounded by double quotes.

Dividing a file into lines
We'll start with a function to import the file and split it into lines.
import = function(content) {
newline = (13.chr() + "?" + 10.chr()).as("RegExp");
content.split(newline)
.tail()
.filter(function(s){s})
}
Line 1 defines the import function, which expects the entire exported file as a single string. Line 2 defines a regular expression which will match the end of a line within the string. Line 3 splits the entire content into an array of lines, each one a string. Line 4 keeps all of the lines except for the first one, which is a header line and not actual data. Finally, line 5 throws away any line which is the empty string (there will be one such after the last newline sequence in the data file), using the fact that KRL treats an empty string as a falsy value.
Alternative way to divide a file into lines
import = function(content) {
content.extract(re#(.+)#g)
.tail()
}
This technique lets the regular expression (applied "globally" (i.e. as many times as needed) to the content) do the work of splitting the file into lines. The String operator extract() will return all matches of "one character (or more) on a line" as an array of strings. We still discard the first (header) line, but no longer need to filter out empty lines.
Obtaining an input file
While it would be possible to make a query to the import function and pass it the entire exported file as a string, we found it preferable to have the function obtain the data file from a URL.
import = function(url) {
newline = (13.chr() + "?" + 10.chr()).as("RegExp");
http:get(url){"content"}.split(newline)
.tail()
.filter(function(s){s})
}
WIth this change, we can call the import function, passing it the URL where it will get the contents of the exported data and split it into lines.
Parsing a line
Having a file divided into lines may be enough for some pico-based applications. In the case we are discussing, there is some structure, a pattern, to each line.
graduand_map = function(line) {
line.extract(re#^([\w ]+),(\w+),(\d+),(\d+),(.*)$#)
}
import = function(url) {
newline = (13.chr() + "?" + 10.chr()).as("RegExp");
http:get(url){"content"}.split(newline)
.tail()
.filter(function(s){s})
.map(function(s){graduand_map(s)})
}
New line 9 in the import function maps each line into whatever is returned by the new function graduand_map to which it passes each line.
Line 2 in that function divides each line into an array of five parts by pattern matching. So, now, the import function returns an array of arrays.
Modifying the graduand_map function as follows will make the import function return an array of maps instead, with each map having the keys "fn", "ln", "id", and "hf".
graduand_map = function(line) {
parts = line.extract(re#^([\w ]+),(\w+),(\d+),(\d+),(.*)$#);
{ "fn": parts[0],
"ln": parts[1],
"id": parts[2].as("Number")*10 + parts[3].as("Number"),
"hf": parts[4]
}
}
In this specific case, it was desirable to combine the values in the third and fourth columns into a single identifier.
Dealing with double quoted values
We add a new function to handle the value from the fifth column by simply removing the double quotes (if present), and splitting it on commas.
hall_of_fame = function(hf) {
hf.replace(re#"#g,"").split(re#, #)
}
graduand_map = function(line) {
parts = line.extract(re#^([\w ]+),(\w+),(\d+),(\d+),(.*)$#);
{ "fn": parts[0],
"ln": parts[1],
"id": parts[2].as("Number")*10 + parts[3].as("Number"),
"hf": hall_of_fame(parts[4])
}
}
The splitting, which produces an array of strings for the fifth column, "hf", value, is done in line 2. Be sure to notice the "g" after the regular expression. This instructs the replace operator to remove not just the first instance of a double quote character, but to do it globally.
The hall_of_fame function is called on each line of the data file in line 9.
Dealing with infrequent values
We modify the graduand_map function as shown.
graduand_map = function(line) {
parts = line.extract(re#^([\w ]+),(\w+),(\d+),(\d+),(.*)$#);
{ "fn": parts[0],
"ln": parts[1],
"id": parts[2].as("Number")*10 + parts[3].as("Number"),
"hf": parts[4] => hall_of_fame(parts[4]) | null
}.filter(function(v,k){v})
}
Notice the use of a ternery expression in line 6 so that we don't call the hall_of_fame function when the fifth column has no value (i.e. is the empty string), but rather puts a null in the "hf" field of the map that it returns. Finally, line 7 filters out any null values from the returned map, which means that records with no fifth column string will have a map without the "hf" key.
Saving the imported data
What we will need is a rule (two rules in our case) to react to availability of the import data.
rule intialization {
select when graduands_collection csv_available where ent:graduands.isnull()
fired {
ent:graduands := {};
}
}
rule import_graduands_collection {
select when graduands_collection csv_available
foreach import(event:attr("url")) setting(map)
pre {
key = "g" + (map{"id"}.as("String"));
}
fired {
ent:graduands{key} := map;
}
}
The initialization rule will fire first, if applicable, making ent:graduands an empty map.
The import_graduands_collection rule will then fire. Line 9 specifies that the remainder of the rule will repeat for each map in the array returned by the import function. It constructs a key for each of these, and uses that key to store the map into ent:graduands in line 14.
After importing the sample data file, this is what the corresponding entries look like in the map stored in ent:graduands.

Importing corrected data files
Data changes, it's just a fact of life. One way to deal with this is to delete the entity variable (manually, in the "Rulesets" tab for the pico), and send the graduands_collection:csv_available event again. Having deleted the entity variable, the initialization rule will fire again before the import begins.
Computation within foreach
In a related project, the raw data didn't include something that could be used as a key. Instead of a unique position within a page, we only have a row number:
First,Last name,Page,Row Paul,Blogorodow,43,1 David,Braun,43,1 Brian,Duell,43,1 Earl,Hall,43,1 Rodney,Haynes,43,2 Cheryl,Jensen,43,2 Laurie,Jensen,43,2 Gordon,Layton,43,2 Duncan,Loree,43,3 Shirley,O'Donnell,43,3 Logan,Porter,43,3 Bob,Vik,43,3 Blair,Valgardson,43,4 Linda,Wall,43,4
We'll use an import function similar to the one used previously (tweaked to allow for a surname like "O'Donnell").
Then, in the rule which does the import from a CSV file into an entity variable, we'll use logic to compute a number within each row, and use that to make our key unique.
rule import_undergraduates_collection {
select when undergraduates_collection csv_available
foreach import(event:attr("url")) setting(map)
pre {
row = map{"id"};
num_on_row = row == ent:last_row => ent:last_num_on_row + 1 | 1;
key = "u" + row + num_on_row;
}
fired {
ent:undergraduates{key} := map;
ent:last_row := row;
ent:last_num_on_row := num_on_row;
}
}
The logic requires keeping track of the last row value seen and the last number seen within the current row. Notice that in the prelude we don't use names bound to values, but rather entity variables.
The first time we reference ent:last_row its value will be null (which will not be equal to the first row value we see). The first time we reference ent:last_num_on_row its value will be 1.
If we want to clean up these entity variable, we can either do it manually in the UI after completing the import, or use the on final guard condition in the postlude. The postlude would then look like:
fired {
ent:undergraduates{key} := map;
ent:last_row := row;
ent:last_num_on_row := num_on_row;
clear ent:last_row on final;
clear ent:last_num_on_row on final;
}
The clearing will then only happen on the last iteration of the foreach, when we know that we won't be needing these values again.
Copyright Picolabs | Licensed under Creative Commons.